La inteligencia artificial AlphaZero ya juega y aprende como un súperhombre
La máquina desarrollada por DeepMind cuenta con un algoritmo más sencillo y versátil que le permite aprender de cero y dominar el ajedrez, el go y el shogi

Cuentan las leyendas sobre el origen del ajedrez que un rey estaba tan fascinado por su creación, que le ofreció a su inventor, en algunas historias un matemático, el derecho de elegir su recompensa. Este le pidió un premio aparentemente humilde. Debía recibir un grano ... de trigo por la primera casilla, dos por la segunda y cuatro por la tercera, duplicando la cantidad cada vez, en cada una de las 64 casillas. La cantidad final, que el tesorero del cuento tardó en calcular bastante tiempo, habría sido capaz de llevar a la quiebra a cualquier reino . De hecho, en el mundo real la deuda no se podría haber pagado ni con la producción mundial de trigo acumulada durante toda la historia.
Noticias relacionadas
Estas 64 casillas ocupan un espacio pequeño y finito, pero ofrecen tantas posibilidades y combinaciones, que los hombres han necesitado milenios para perfeccionar sus jugadas, y aun así no han llegado nunca a la partida perfecta. Pero allá donde la sabiduría y el ingenio solo pueden acercarse, quizás llegue la inteligencia artificial (IA). Una IA perfeccionada y desarrollada ya durante más de medio siglo, tal como demostró Deep Blue en 1997, cuando derrotó al campeón mundial, Gary Kasparov.
AlphaZero, el campeón que aprende
Han pasado veinte años desde aquello. Hoy, uno de los campeones más implacables de la IA es AlphaZero , un programa de ordenador desarrollado por la compañía DeepMind y que nace de AlphaGo, que fue capaz de derrotar al mejor jugador de go del mundo . AlphaZero es capaz de alcanzar un nivel de maestría sobrehumana en el ajedrez, el go y el shogi, y además lo hace aprendiendo. Puede aprender desde cero, tan solo conociendo las reglas, en solo 24 horas, sencillamente por el hecho de jugar contra sí mismo. Ya no necesita que nadie programe reglas que debe seguir, o hacer infinidad de cálculos antes de cada jugada.
Hace un año, DeepMind publicó un borrador en el que demostraba que AlphaZero, era capaz de derrotar a los programas más avanzados para jugar a los tres juegos comentados: Stockfish, Elmo y el propio AlphaGo Zero. Lo hizo usando circuitos diseñados para permitir el aprendizaje maquinal y basados en redes neurales . Todos ellos le permitían a esta IA no solo alcanzar un rendimiento extraordinario, sino también acomodarse a una gama más amplia de reglas. Estos logros acaban de publicarse en la revista Science .
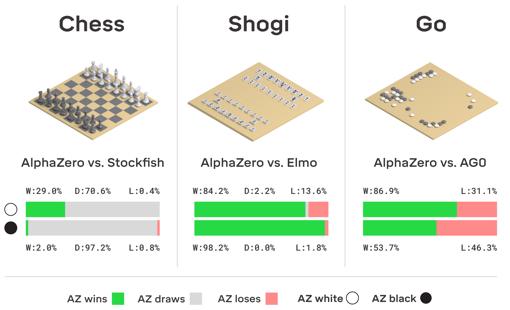
«Nuestros resultados demuestran que un algoritmo de aprendizaje por refuerzo y de propósito general puede aprender, partiendo de cero –sin necesidad de añadir conocimientos o datos previos, proporcionados por humanos, solo conociendo las reglas– y alcanzar un rendimiento sobrehumano en varios juegos de gran complejidad », han escrito los autores de la investigación, dirigida por David Silver . Por tanto, AlphaZero representa un importante paso adelante en la tarea de crear una avanzada inteligencia artificial capaz de dominar juegos más complejos por su cuenta.
«El objetivo de DeepMind es construir sistemas que puedan solucionar algunos de los problemas más complejos del mundo y crear un programa que puede enseñarse a sí mismo cómo dominar el ajedrez, el shogi y el go desde cero es un importante primer paso en ese camino », ha dicho en un comunicado Demis Hassabis , director y cofundador de DeepMind.
Por su parte, Silver ha dicho que su sueño sería «ver el mismo tipo de sistema aplicado no solo a juegos de mesa, sino a todo tipo de aplicaciones reales, como por ejemplo, el diseño de medicamentos, el diseño de materiales o la biotecnología».
Aprendizaje a partir de refuerzo
Pero, ¿cómo funciona AlphaZero? Según ha escrito Murray Campbell , investigador de IBM, en un artículo de análisis publicado en Science , «AlphaZero está basado en el aprendizaje a partir de refuerzo, un paradigma muy general para aprender a actuar en un medio que recompensa las acciones útiles». En el caso de los juegos de mesa, la IA se entrena jugando un gran número de partidas contra sí misma.
En los últimos años, se ha aplicado las redes neurales y el aprendizaje profundo («deep», en inglés) a este proceso basado en el refuerzo. En esta ocasión, la investigación dirigida por Silver ha mejorado este aprendizaje profundo creando un algoritmo, el árbol de búsqueda de Monte Carlo (MCTS, en inglés), que ya se usaba en go, para aprender nuevos juegos. El sistema parte de parámetros generados aleatoriamente y la red neural los va modificando poco a poco.
Un jugador flexible
Según ha dicho en un comunicado Yoshiharu Habu , el segundo jugador de la historia con más títulos de shogi, este aprendizaje convierte a AlphaZero en «un jugador flexible que prefiere hacer aperturas destinadas a ataques rápidos cuando comienza a jugar, pero que juega a la defensiva cuando empieza en segundo lugar».
Además, resulta creativo: «Algunos de sus movimientos, como mover el rey al centro del tablero, van contra la teoría del shogi y, desde la perspectiva humana, ponen a AlphaZero en la que parece ser una posición peligrosa . Pero, increíblemente, conserva el control del tablero». Tan eficaz es esta IA, que Habu cree que su estilo de juego muestra que existen nuevas posibilidades por explorar en este centenario juego de tablero.
Los próximos juegos que dominar
Sin embargo, Murray Campbell ha destacado que todos estos logros han sido alcanzados en un entorno propicio para las IAs. Fundamentalmente, porque estos juegos permiten al jugador observar todo lo que hace el rival y se cuenta con toda la información necesaria para tomar decisiones, no como en el póquer, donde lo que no se sabe tiene un importante peso. Además, estos juegos de tablero «tienen dos jugadores, son de suma cero , deterministas, estáticos y discretos», lo que hace, según el investigador de IBM, que sea más fácil simular perfectamente la evolución del juego a través de secuencias arbitrarias de jugadas».
Por ello, Campbell ha sugerido que los desarrolladores necesitan ahora buscar una nueva generación de juegos para proporcionarle nuevos retos a las IAs, como pueden ser videojuegos como StarCraft II o Dota , en los que la información solo es parcial y donde hay una gran diversidad de acciones y posibilidades. Tantas que pondrían en apuros a un programa como AlphaZero. ¿Acabará venciendo una IA a los mejores jugadores de videojuegos del mundo?
Esta funcionalidad es sólo para suscriptores
Suscribete
Esta funcionalidad es sólo para registrados
Iniciar sesiónEsta funcionalidad es sólo para suscriptores
Suscribete